Enterprise Local LLM Foundry (v1.0) – Die Wissensfabrik hinter der Firewall
Einleitung: Wenn KI-Modelle zur Schule gehen
In einer Welt, in der große Sprachmodelle wie GPT-4 oder Claude täglich Millionen von Anfragen beantworten, stand ich vor einer zentralen Herausforderung: Wie bringe ich einem KI-Modell bei, das spezifische Fachwissen eines Unternehmens zu verstehen, ohne dass sensible Daten jemals das interne Netzwerk verlassen? Mit der Enterprise Local LLM Foundry habe ich eine Antwort auf diese Frage entwickelt – eine Plattform, die generische Basis-Modelle in spezialisierte Fach-Experten verwandelt, vollständig auf der eigenen Hardware, ohne Cloud-Anbindung.
Die zentrale Formel, die ich verfolge, ist bestechend einfach: Basis-LLM + lokales Wissen = intelligenteres Fach-LLM. Doch die technische Umsetzung dieser Vision war alles andere als trivial. Ich habe eine geschlossene Produktionskette entwickelt, die unstrukturierte Dokumente aufnimmt und am Ende ein einsatzbereites, optimiertes KI-Modell ausspuckt.
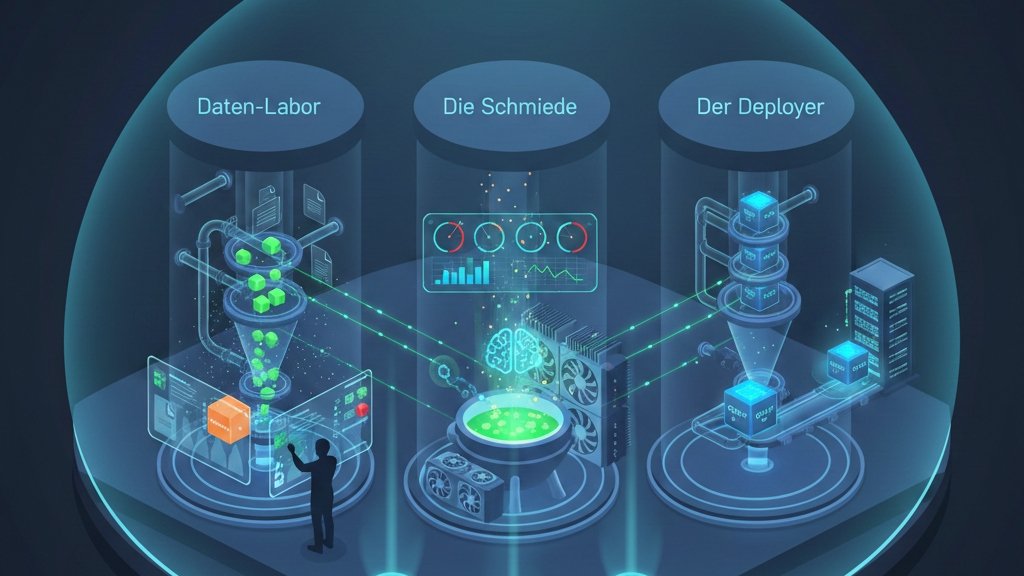
Die Architektur: Drei Säulen, eine Mission
Säule A: Das Daten-Labor – Wo Wissen zu KI-Nahrung wird
Der erste Schritt jeder Modellveredelung beginnt mit der Datenaufbereitung. Das Daten-Labor meiner Foundry übernimmt die Aufgabe, aus rohen Dokumenten strukturiertes Trainingsmaterial zu erzeugen.
Ich habe einen Universal Ingest entwickelt, der Dokumente verschiedenster Formate (PDF, TXT, Markdown) einliest und in semantisch sinnvolle Abschnitte zerlegt. Diese Chunks werden nicht einfach wahllos geschnitten, sondern so segmentiert, dass zusammenhängende Informationen erhalten bleiben.
Herzstück dieses Prozesses ist das Wissens-Staging-System, das ich implementiert habe. Jedes automatisch generierte Frage-Antwort-Paar durchläuft einen dreistufigen Qualitätsprozess: Zunächst landet es im Status "Pending", wo es auf menschliche Prüfung wartet. Von dort aus kann es entweder in "Approved" befördert oder als "Trash" markiert werden. Diese Dreistufigkeit ist keine bürokratische Spielerei, sondern eine bewusste Design-Entscheidung: Ich wollte garantieren, dass kein fehlerhaftes oder irrelevantes Wissen in das finale Modell einfließt.
Besonders wichtig war mir: Die menschliche Hoheit bleibt jederzeit gewahrt. Nutzer können jedes generierte Trainingsdatum im integrierten Editor öffnen, korrigieren und bei Bedarf komplett umschreiben. Die Maschine schlägt vor, der Mensch entscheidet.
Die Benutzeroberfläche zeigt dabei eine transparente Bilanz: Wie viele Dateien wurden verarbeitet? Wie viele Wissens-Einheiten wurden extrahiert? Wie viele davon sind bereits freigegeben? Diese Metriken schaffen Vertrauen und ermöglichen eine präzise Kontrolle über den Veredelungsprozess.
Säule B: Die Schmiede – Wo Wissen mit Modellen verschmilzt
Wenn das Wissen vorbereitet ist, beginnt der eigentliche Veredelungsprozess in der "Forge". Hier habe ich die Verschmelzung des freigegebenen Trainingsmaterials mit dem Basis-Modell implementiert – ein Prozess, der ohne die richtigen Werkzeuge Hardware und Geduld gleichermaßen strapazieren würde.
Das Hardware-Cockpit bildet das Nervenzentrum der Schmiede. In der Sidebar habe ich ein permanentes Echtzeit-Monitoring eingebaut, das die GPU-Auslastung und den verfügbaren VRAM anzeigt. Diese Information ist kritisch: Wer versucht, ein zu großes Modell auf zu schwacher Hardware zu trainieren, riskiert Systemabstürze oder endlose Wartezeiten.
Bevor das Training beginnt, führt meine Foundry automatische Checks durch: Ist CUDA verfügbar? Stimmt die Datenqualität? Sind die Pfade korrekt konfiguriert? Diese Boot-Guardrails habe ich entwickelt, um frustrierende Fehlermeldungen nach stundenlangem Warten zu verhindern.
Während des Trainings läuft die Live-Telemetrie, die ich implementiert habe, auf Hochtouren. Über JSON-strukturierte Logs sieht der Nutzer in Echtzeit, wie sich der Trainings-Loss entwickelt, welche Epoche gerade läuft und wie lange der Prozess voraussichtlich noch dauert. Diese Transparenz war mir besonders wichtig: Sie verhindert den Eindruck eines eingefrorenen Systems und gibt dem Nutzer jederzeit die Möglichkeit, den Prozess zu unterbrechen, falls die Hardware überlastet ist.
Säule C: Der Deployer – Vom Prototyp zum Produktivsystem
Ein veredeltes Modell ist nur dann wertvoll, wenn es einfach in bestehende Workflows integriert werden kann. Ich habe den Deployer entwickelt, um diese letzte Meile zu bewältigen.
Das fertige Modell wird im GGUF-Format exportiert – einem hocheffizienten Dateiformat, das speziell für die Ausführung von LLMs auf lokaler Hardware optimiert wurde. Im Gegensatz zu klassischen PyTorch-Checkpoints benötigt GGUF deutlich weniger Speicher und lädt schneller.
Die sichere Registrierung, die ich implementiert habe, verhindert versehentliches Überschreiben: Wird ein Modell mit einem Namen exportiert, der bereits existiert, hängt das System automatisch eine Versionsnummer an (_v1, _v2 usw.). Jedes Modell wird zusammen mit seinem "Bauplan" – einem Modelfile, das alle Konfigurationsparameter enthält – archiviert. Damit lässt sich später exakt nachvollziehen, wie ein bestimmtes Modell entstanden ist.
Die technische Magie: Vier Innovationen unter der Haube
1. 4-Bit Quantization mit Unsloth
Das Training großer Sprachmodelle erfordert normalerweise teure Rechenzentren mit mehreren High-End-GPUs. Ich habe diese Barriere durch den Einsatz von 4-Bit Quantization durchbrochen. Die Unsloth-Bibliothek ermöglicht es mir, Modelle mit 8 Milliarden Parametern auf Consumer-Grafikkarten mit nur 12 GB VRAM zu trainieren – eine Demokratisierung, die vor wenigen Jahren undenkbar gewesen wäre.
2. LoRA/PEFT: Effizienz durch intelligente Anpassung
Statt das gesamte Modell neu zu trainieren – ein Prozess, der Tage dauern und Tausende Euro an Rechenkosten verursachen kann – setze ich auf Low-Rank Adaptation (LoRA). Diese Technik fügt dem Basis-Modell kleine, trainierbare Adapter-Schichten hinzu, während der Großteil der ursprünglichen Gewichte eingefroren bleibt. Das Ergebnis: Trainingszeiten von Stunden statt Tagen bei vergleichbarer Qualität.
3. Multi-threaded Log Parsing
Eine der größten Herausforderungen bei langwierigen Berechnungen ist die Benutzerführung. Niemand möchte minutenlang auf einen schwarzen Bildschirm starren und sich fragen, ob das System noch arbeitet oder abgestürzt ist. Ich habe dieses Problem durch asynchrones Log-Streaming gelöst: Während der Trainingsprozess in einem Unterprozess läuft, liest die Benutzeroberfläche kontinuierlich die Ausgaben aus und stellt sie formatiert dar – ohne die Performance zu beeinträchtigen.
4. Pydantic Validation: Qualität durch Struktur
Jede synthetisierte Trainingsdaten-Einheit durchläuft eine strikte Schema-Validierung mit Pydantic, die ich implementiert habe. Dies verhindert, dass fehlerhafte oder unvollständige Daten in die Trainings-Pipeline gelangen. Die Validierung prüft nicht nur die Datentypen, sondern auch semantische Konsistenz – etwa ob eine Antwort tatsächlich zur gestellten Frage passt.
Die Error-Datenbank: Lernen aus gelösten Problemen
Jede robuste Software basiert auf systematischer Fehlerbeseitigung. Ich habe alle aufgetretenen und gelösten Probleme in einer strukturierten Error-Datenbank dokumentiert:
ERR-20251222-JSON-DATE: Ein scheinbar harmloser Fehler beim Serialisieren von Datum-Objekten führte zu Abstürzen der API. Meine Lösung: konsequenter Einsatz von Pydantic-Schemas für alle API-Responses.
ERR-20260110-FILE-DUPE: Frühe Versionen nutzten Zeitstempel für die Benennung exportierter Modelle – eine Strategie, die bei schnellen aufeinanderfolgenden Exporten zu Kollisionen führte. Ich habe eine Inkrement-Logik implementiert, die das Problem elegant löste.
ERR-20251212-MIG-LOCK: Bei Optimierungsprozessen, die mehrere Minuten dauerten, fehlte visuelles Feedback. Nutzer berichteten von vermeintlichen "Einfrierungen". Ich habe Live-Progress-Streams eingeführt und damit dieses Problem vollständig eliminiert.
Diese systematische Fehlererfassung ist mehr als Dokumentation – sie ist die Grundlage für kontinuierliche Verbesserung und verhindert, dass gelöste Probleme erneut auftreten.
Meine Design-Verfassung: Prinzipien mit System
Ich habe meine Design-Philosophie in einer Art "Verfassung" kodifiziert – einem Regelwerk, das die Entwicklung der gesamten Plattform durchzieht:
Transparenz (Glass-Box-Prinzip): Jeder Prozess ist messbar und nachvollziehbar. Keine Black-Box-Magie, keine versteckten Automatismen. Was das System tut, zeigt es auch.
Revidierbarkeit (Undo-Garantie): Jede Löschaktion ist zunächst ein Soft-Delete. Dateien landen im Trash-Ordner, aus dem sie wiederhergestellt werden können. Erst eine bewusste "Leeren"-Aktion macht Änderungen irreversibel.
Progressive Offenlegung: Technische Details werden nicht erschlagen, sondern schrittweise enthüllt. Ein Anfänger sieht nur die wesentlichen Bedienelemente, ein Experte kann tiefer ins System eintauchen.
Menschliche Hoheit: Die finale Entscheidung – über Wissen, über Training, über Deployment – liegt immer beim Menschen. Das System assistiert, aber diktiert nicht.
Diese Prinzipien sind nicht nur theoretische Leitlinien, sondern finden sich in jedem Detail meiner Implementierung wieder: vom dreistufigen Staging-System über das Hardware-Monitoring bis zur versionierten Modell-Registrierung.
Fazit: Die Demokratisierung der KI-Veredelung
Die Enterprise Local LLM Foundry ist mehr als ein Werkzeug – sie ist meine Antwort auf eine der drängendsten Fragen der aktuellen KI-Ära: Wie können Organisationen die Vorteile großer Sprachmodelle nutzen, ohne Kompromisse bei Datenschutz und Kontrolle einzugehen?
Indem ich die gesamte Pipeline – von der Datenaufbereitung über das Training bis zum Deployment – in eine kohärente, beherrschbare Plattform integriert habe, konnte ich die Einstiegshürden drastisch senken. Was früher ein Team aus ML-Engineers, DevOps-Spezialisten und Datenarchitekten erforderte, kann nun von einem einzelnen technisch versierten Mitarbeiter bewerkstelligt werden.
Die Version 1.0 ist dabei erst der Anfang. Die modulare Architektur und die klare Trennung der drei Säulen, die ich entwickelt habe, schaffen die Grundlage für zukünftige Erweiterungen: Multi-GPU-Support, verteiltes Training, automatische Hyperparameter-Optimierung. Doch bereits in ihrer aktuellen Form beweist meine Foundry, dass On-Premise-KI-Entwicklung keine Utopie mehr ist, sondern gelebte Praxis – gestaltet nach den Prinzipien, die ich in meiner Verfassung niedergelegt habe.